Amazon Textract
Amazon Textract is a fully managed AI/ML service that automatically:
Extracts printed or handwritten text, forms, tables, and even checkboxes from scanned documents and images.- Supports
key-value pair extraction, which is especially useful for processing structured documents like invoices, tax forms, and medical records. - Requires no templates or manual configuration, unlike traditional OCR tools.
- Integrates well with AWS services for automation, analytics, and document workflows.
- It's designed for use cases like
document processing automation, compliance, anddata entry elimination.
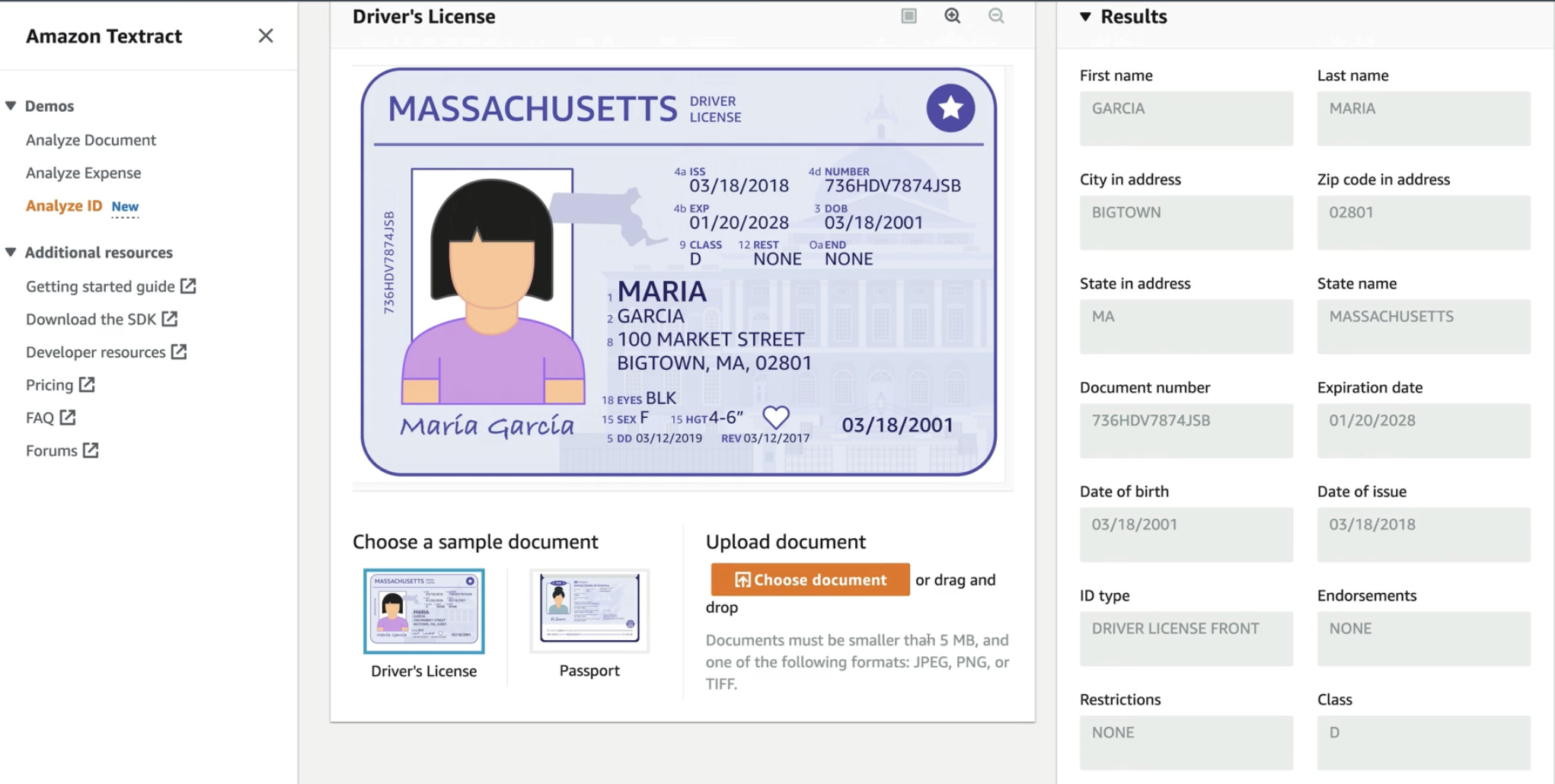
Question: Textract and Comprehend
A hospital recently deployed a RESTful API with Amazon API Gateway and AWS Lambda. The hospital uses API Gateway and Lambda to upload reports that are in PDF format and JPEG format. The hospital needs to modify the Lambda code to identify protected health information (PHI) in the reports. Which solution will meet these requirements with the LEAST operational overhead?
- Use Amazon Textract to extract the text from the reports. Use Amazon SageMaker to identify the PHI from the extracted text.
Use Amazon Textract to extract the text from the reports. Use Amazon Comprehend Medical to identify the PHI from the extracted text.(Correct Ans)- Use Amazon Rekognition to extract the text from the reports. Use Amazon Comprehend Medical to identify the PHI from the extracted text.
Explanation:
- Amazon Textract is ideal for extracting text from PDF and JPEG reports, including forms and tables.
- Amazon Comprehend Medical is specifically designed to detect protected health information (PHI) and medical entities from text using NLP models trained for healthcare.
This combination (Textract + Comprehend Medical) is fully managed, scalable, and minimizes operational effort.
Why not other options?
- Amazon SageMaker: Requires building and training your own model, which adds significant operational overhead.
- Amazon Rekognition: Best for image and video analysis, not text extraction.