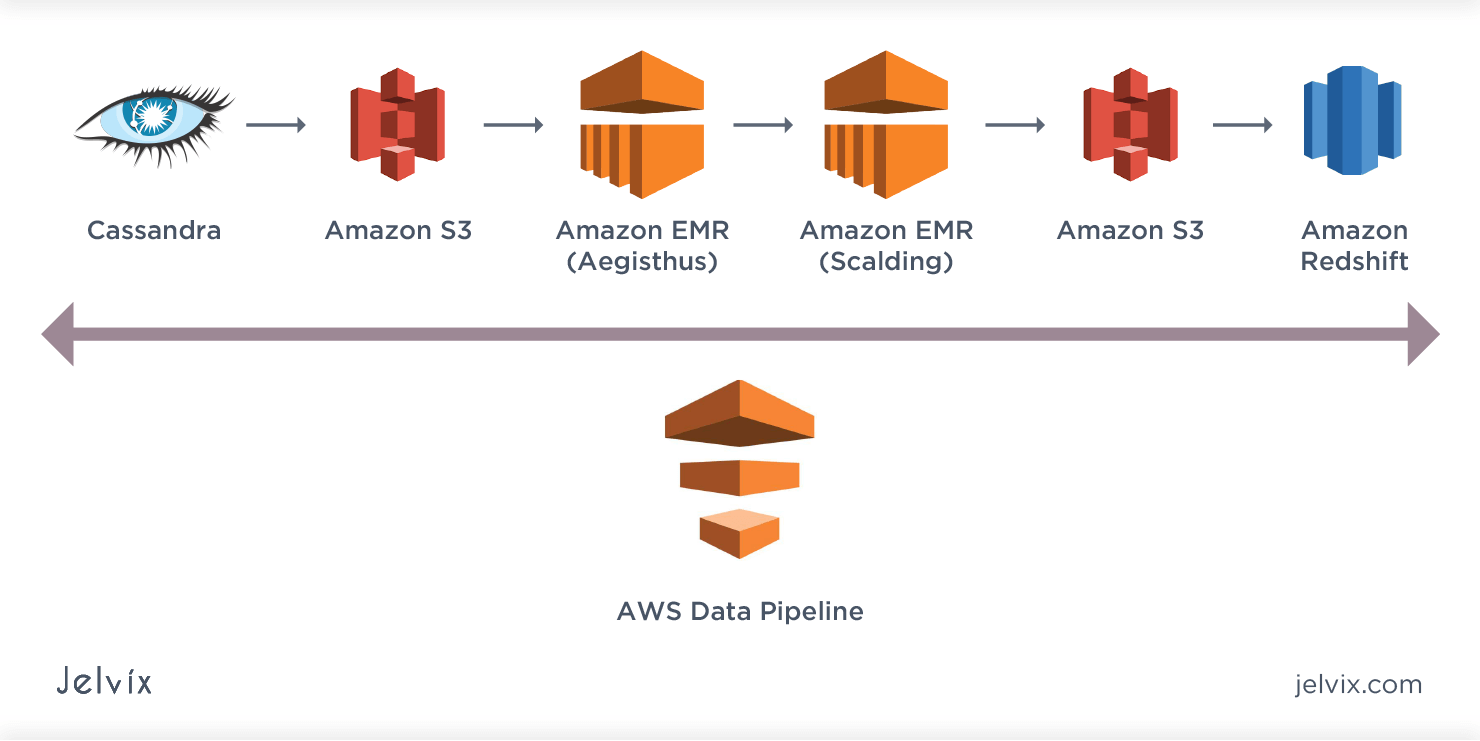
AWS Data Pipeline
AWS Data Pipeline is a web service that helps automate the movement, transformation, and processing of data across various AWS services and on-premises data sources.
Example: Use AWS Data Pipeline to copy data from an Amazon S3 bucket to an Amazon Redshift cluster daily, transforming the data into an analytics-ready format during the process.
1. Why to choose AWS Data Pipeline?
AWS offers several other services like AWS Glue, AWS Step Functions, and AWS Lambda that can handle data transfer, transformation, and orchestration. So, why choose AWS Data Pipeline specifically? Ans - AWS Data Pipeline:
- Allows to create complex data workflows by combining various AWS services (S3, Redshift, EMR, Lambda, etc.) into a single automated process.
- Provides built-in scheduling options, so you can define when and how frequently your data transfers and transformations occur, without needing manual intervention.
- Offers built-in error handling and retries, making it more resilient to failures, compared to other point solutions like AWS Lambda or Step Functions.