AWS Glue
Fully managed ETL (Extract, Transform, Load) service that organizes messy files into a database-like structure for analytics. Supports both batch and real-time streaming ETL.
1. Components
- Glue Job: A core ETL task
where data transformations occur, using Spark-based scripts in Python or Scala. - Data Catalog:
Repository that manages schemas and tables, enabling data discovery and integration with querying tools like Athena and Redshift. - Crawlers: Automated tools that
scan data sources, infer schema, and update the Data Catalog. - AWS Glue DataBrew: A visual data preparation tool that
enables profiling, cleaning, and transformation without code, aimed at non-developers for easier data wrangling.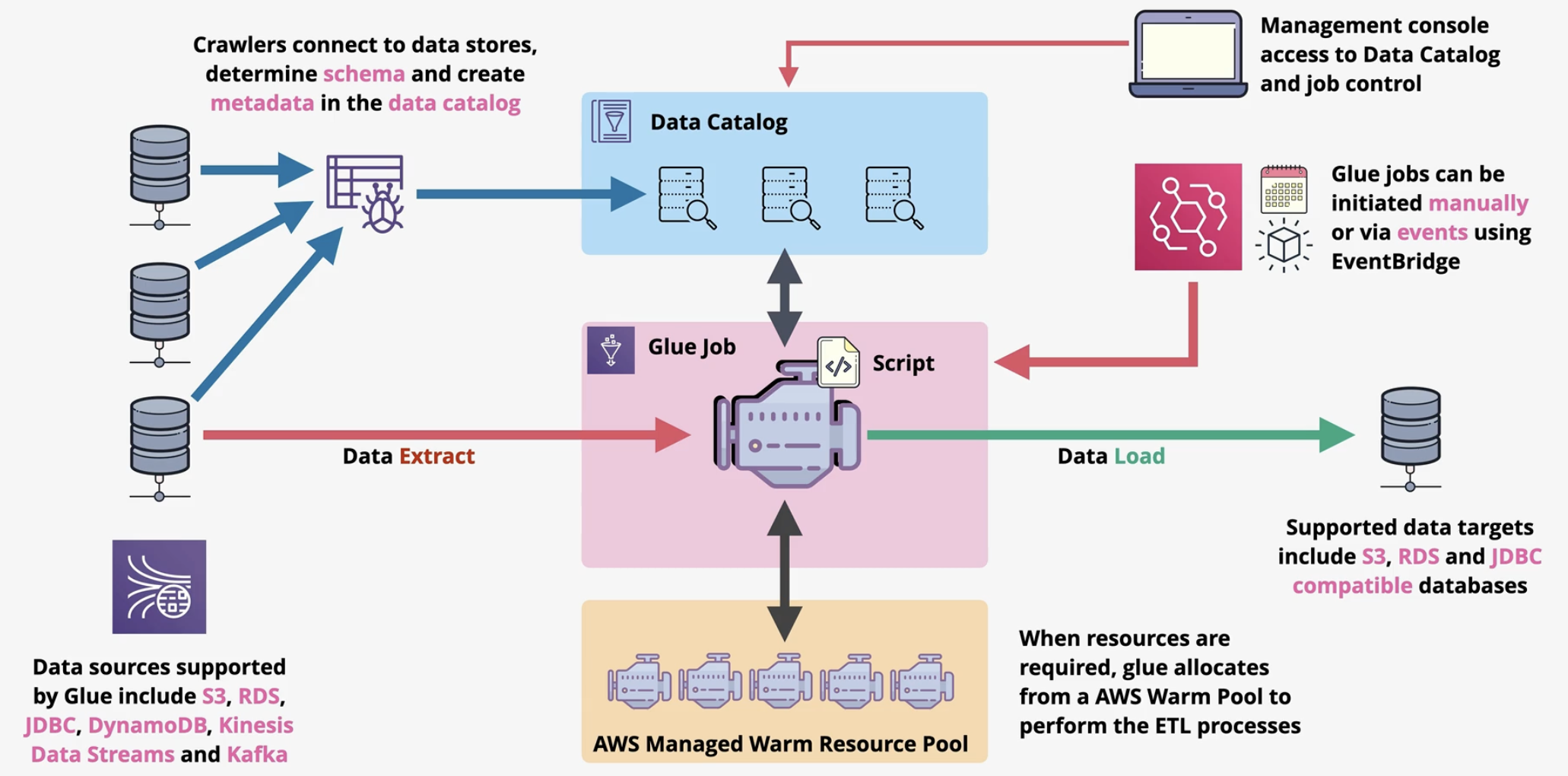
2. Job Bookmark
AWS Glue Job Bookmarks are a feature that enables an ETL job to track the progress of data that has already been processed. This ensures that only new data is processed during subsequent runs. By enabling job bookmarks, you avoid reprocessing old data, which saves time and cost.
3. CommonUse Case
- Optimized for serverless ETL within AWS
- Use AWS data pipeline for
custom, complex workflowsthat require detailed control over processing steps and resources
4. Question
A company has an AWS Glue extract, transform, and load (ETL) job that runs every day at the same time. The job processes XML data that is in an Amazon S3 bucket. New data is added to the S3 bucket every day. A solutions architect notices that AWS Glue is processing all the data during each run.
What should the solutions architect do to prevent AWS Glue from reprocessing old data?
- Edit the job to use job bookmarks.
Correct Ans - Edit the job to delete data after the data is processed.
- Edit the job by setting the NumberOfWorkers field to 1.
- Use a FindMatches machine learning (ML) transform.